İstenmeyene Göğüs Gerenler : Filtreler – 3 – Sinyal İşleme Uygulaması
Evet sanırım artık beklediğiniz yazı geldi. Bunca matematik ve onlarca çalışmadan sonra artık bu işin ekmeğini yeme zamanının geldiğini düşünüyorum. Özellikle sinyal işlemede çok özel bir yeri olan “Filtreleme” konusu barındırdığı sihirli matematik ile beni ciddi anlamda büyülemiştir. Bir filtre tasarlamanın birden fazla yolu olması, kalite faktörü, filtrenin cevabı gibi bir çok ayrıntıyı içinde barındırsa da bunların çok da zor olmadığını az çok gördük. Eğer işin temelini anladıysanız gelin sonra bir uygulama ile bu yazı dizisini tamamlayalım.
Öncelikle, eğer okumadıysanız eski yazıları mutlaka okumanızı tavsiye ederim. Bunun sebebi burada kullanacağım filtreleme kodlarını daha önceki yazılarımda anlatmış olmamdır.
Özellikle ses sinyallerini işlerken sıkça kullanılan filtreler daha önceki yazılardan gördüğünüz üzere kendi içinde derya deniz! Önemli olanın uygulamaya göre en iyi filtreyi seçmek olduğunu unutmamak gerekiyor. Ben bu yazıda daha önceden kullandığımız analog filtrenin uygulanışını göstereceğim. Bilinear Z Transform ile bir analog filtrenin nasıl dijital bir filtreye dönüştüğünü anlatmıştım. Şimdi bunu filtreyi Python uygulaması ile ses sinyali üzerinden gerçek zamanlı olarak test edelim.. Bu uygulamayı ayrıca bir mikrodenetleyici üzerinde çalıştırmayı da düşünüyorum. Bunu daha sonraki yazılarda görmeniz olası.
Öncelikle girdi olarak ses sinyalini bilgisayardan alacağımız için bize bir mikrofon veya farklı bir çözüm gerekiyor. Ben bu işi bilgisayarda bulunan “Stereo Karışımı” özelliğini kullanarak yaptım. Python içerisinde bulunan “PyAudio” kütüphanesi ses girdiğini yazılım ile almamızı sağlıyor. Oldukça basit ve kullanışlı olan bu kütüphane bize çok az kodla devasa işleri yapmamızı sağlıyor.
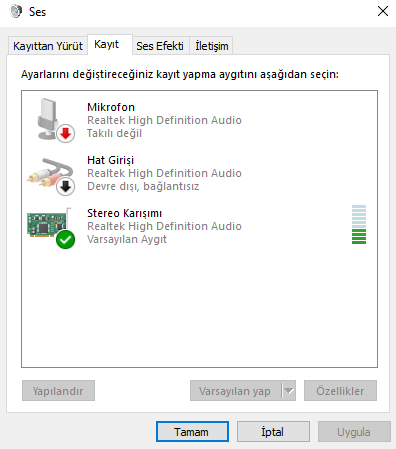
Öncelikle Stereo Karışımını “Varsayılan Aygıt” olarak belirliyoruz. Ardından Python için PyAudio kütüphanesi kurmamız gerekiyor. Bu kütüphanenin kurulumu Windows ortamı için biraz zor olabiliyor. Visual C++ 14 kurulu olması gerekiyor. Ayrıca kullandığınız Python sürümüne uygun kütüphaneyi şu siteden indirip elle kurmanız daha sağlıklı olacaktır.
Elle kurulum için önce pip, setuptools gibi güncellemeleri yapın. Akabinde Python 3.7 64Bit için şu dosyayı yükleyin.
|
1 2 3 |
pip install --upgrade pip pip install --upgrade setuptools pip install PyAudio-0.2.11-cp37-cp37m-win_amd64.whl |
Bu aşamadan sonra programlamaya başlayabiliriz. Ben arayüzünü kullanışlı bulduğum ve geliştirme aşamasından büyük kolaylıklar sağladığı için PyCharm’ı tercih ediyorum. Bir Python dosyası açtıktan sonra aygıtları kontrol etmek adına şu kodu çalıştırıp çıktıyı görmemiz gerekiyor.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
import pyaudio # detect devices: p = pyaudio.PyAudio() host_info = p.get_host_api_info_by_index(0) device_count = host_info.get('deviceCount') devices = [] print("Device Count :", device_count) for i in range(0, device_count): device = p.get_device_info_by_host_api_device_index(0, i) print(device) |
Benim aldığım çıktı şu şekilde.
|
1 2 3 4 5 |
{'index': 0, 'structVersion': 2, 'name': 'Microsoft Ses Eşleştiricisi - Input', 'hostApi': 0, 'maxInputChannels': 2, 'maxOutputChannels': 0, 'defaultLowInputLatency': 0.09, 'defaultLowOutputLatency': 0.09, 'defaultHighInputLatency': 0.18, 'defaultHighOutputLatency': 0.18, 'defaultSampleRate': 44100.0} {'index': 1, 'structVersion': 2, 'name': 'Stereo Karışımı (Realtek High D', 'hostApi': 0, 'maxInputChannels': 2, 'maxOutputChannels': 0, 'defaultLowInputLatency': 0.09, 'defaultLowOutputLatency': 0.09, 'defaultHighInputLatency': 0.18, 'defaultHighOutputLatency': 0.18, 'defaultSampleRate': 44100.0} {'index': 2, 'structVersion': 2, 'name': 'Microsoft Ses Eşleştiricisi - Output', 'hostApi': 0, 'maxInputChannels': 0, 'maxOutputChannels': 2, 'defaultLowInputLatency': 0.09, 'defaultLowOutputLatency': 0.09, 'defaultHighInputLatency': 0.18, 'defaultHighOutputLatency': 0.18, 'defaultSampleRate': 44100.0} {'index': 3, 'structVersion': 2, 'name': 'Hoparlör (Realtek High Definiti', 'hostApi': 0, 'maxInputChannels': 0, 'maxOutputChannels': 8, 'defaultLowInputLatency': 0.09, 'defaultLowOutputLatency': 0.09, 'defaultHighInputLatency': 0.18, 'defaultHighOutputLatency': 0.18, 'defaultSampleRate': 44100.0} {'index': 4, 'structVersion': 2, 'name': 'Realtek Digital Output (Realtek', 'hostApi': 0, 'maxInputChannels': 0, 'maxOutputChannels': 2, 'defaultLowInputLatency': 0.09, 'defaultLowOutputLatency': 0.09, 'defaultHighInputLatency': 0.18, 'defaultHighOutputLatency': 0.18, 'defaultSampleRate': 44100.0} |
Evet Stereo Karışımı listede gözüküyor her şey yolunda.
Şimdi ise ses sinyalini almak için WEB Tarayıcı üzerinden bir Tone Generator kullanabiliriz. Şu site sade ve içerdiği özellikler ile gayet kullanışlı duruyor. Buradan bir sinüs üretip test yapmaya başlayabiliriz.
Araştırma yaparken şurada çok işe yarayacak bir kod bloğu buldum. Bu kodu üzerinde çok ufak bir düzenleme yaparak filtreleme kodunu ekleyip çalıştırmak mümkün. Tone Generator ile önce filtresiz olarak çalıştıralım. Ben bir kaç rakamı değiştirip test yaptım.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 |
#!/usr/bin/env python # encoding: utf-8 ## Module infomation ### # Python (3.4.4) # numpy (1.10.2) # PyAudio (0.2.9) # matplotlib (1.5.1) # All 32bit edition ######################## import numpy as np import pyaudio import matplotlib.pyplot as plt class SpectrumAnalyzer: FORMAT = pyaudio.paFloat32 CHANNELS = 1 RATE = 16000 CHUNK = 2048 START = 0 N = 2048 wave_x = 0 wave_y = 0 spec_x = 0 spec_y = 0 data = [] def __init__(self): self.pa = pyaudio.PyAudio() self.stream = self.pa.open(format = self.FORMAT, channels = self.CHANNELS, rate = self.RATE, input = True, output = False, frames_per_buffer = self.CHUNK) # Main loop self.loop() def loop(self): try: while True : self.data = self.audioinput() self.fft() self.graphplot() except KeyboardInterrupt: self.pa.close() print("End...") def audioinput(self): ret = self.stream.read(self.CHUNK) ret = np.fromstring(ret, np.float32) return ret def fft(self): self.wave_x = range(self.START, self.START + self.N) self.wave_y = self.data[self.START:self.START + self.N] self.spec_x = np.fft.fftfreq(self.N, d = 1.0 / self.RATE) y = np.fft.fft(self.data[self.START:self.START + self.N]) self.spec_y = [np.sqrt(c.real ** 2 + c.imag ** 2) for c in y] def graphplot(self): plt.clf() # wave plt.subplot(311) plt.plot(self.wave_x, self.wave_y) plt.axis([self.START, self.START + self.N, -1, 1]) plt.xlabel("time [sample]") plt.ylabel("amplitude") #Spectrum plt.subplot(312) plt.plot(self.spec_x, self.spec_y, marker= '', linestyle='-') plt.axis([0, self.RATE / 2, 0, 50]) plt.xlabel("frequency [Hz]") plt.ylabel("amplitude spectrum") #Pause plt.pause(.01) if __name__ == "__main__": spec = SpectrumAnalyzer() |
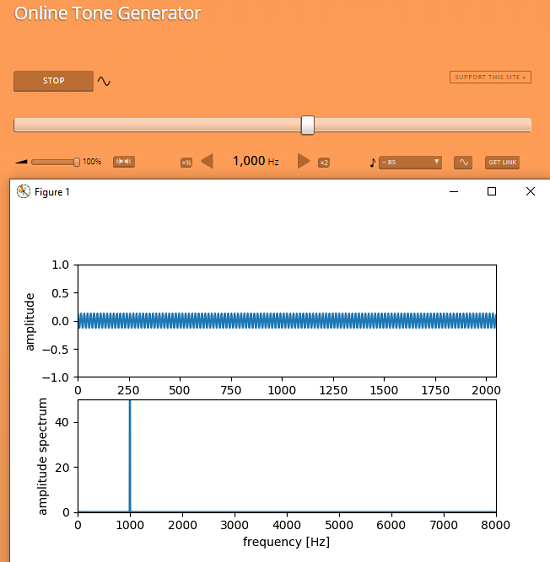
Evet bu adımda değerler çok tutarlı. Bir sonraki adımda filtreleme kodunu ekleyebiliriz. Ben ekleme işini yapmadan önce daha önce yazdığımız filtre kodunda ufak bir düzenleme yaptım. Bu K1, K2 ve K3 katsayılarının sadece 1 defa hesaplanmasını sağlıyor. Sürekli olarak bunu hesaplamaya gerek yok. Eski ve yeni filtreleme kodlarını inceleyerek bu ufak farkı görebilirsiniz. Aşağıda güncel hali mevcut. Bunu projeye ekleyerek filtreleme işini başlatalım.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
from scipy import arctan, pi class LowPassFilter(object): def __init__(self, x, R, C, period): self.__R = R self.__C = C self.__T = period self.__y = [0] * len(x) self.__K1 = (self.__T / (self.__T + 2 * self.__R * self.__C)) self.__K2 = (self.__T / (self.__T + 2 * self.__R * self.__C)) self.__K3 = ((self.__T - 2 * self.__R * self.__C) / (self.__T + 2 * self.__R * self.__C)) def FilterApply(self, __x): for i in range(len(__x)): self.__y[i] = (__x[i] * self.__K1) + (__x[i - 1] * self.__K2) - (self.__y[i - 1] * self.__K3) return (self.__y) def GetFrequency(self): return (1 / (2 * pi * self.__R * self.__C)) def GetWarping(self): return (2 / self.__T) * arctan(2 * pi * self.GetFrequency() * self.__T / 2) / (2 * pi) |
Yazılım içerisinde gerekli düzenlemeleri yaparken önce R, C ve Ts değerlerini girelim.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
class SpectrumAnalyzer: FORMAT = pyaudio.paFloat32 CHANNELS = 1 RATE = 16000 CHUNK = 2048 START = 0 N = 2048 R = 1000 # R Ohm C = 150e-9 # C Farad Ts = 1.0 / RATE # sampling Frequency wave_x = 0 wave_y = 0 spec_x = 0 spec_y = 0 data = [0] * CHUNK filteredata = [] myFilter = Filter.LowPassFilter(data, R, C, Ts) ... |
Son olarak filtreleme kodunu döngüye ekleyelim.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
def loop(self): try: while True : # Ses Alımı Başladı. self.data = self.stream.read(self.CHUNK) self.data = np.fromstring(self.data, np.float32) # Filtreleme. if filterState == 1: self.filteredata = self.myFilter.FilterApply(self.data) self.data = self.filteredata # FFT Alma. self.fft() # Grafiğe Aktarılıyor. self.graphplot() except KeyboardInterrupt: print("End...") |
Tüm yapacaklarımız bundan ibaret. Artık filtrenin keyfini çıkarabilirsiniz. Hatta aynı anda çalıştırıp farkı incelemeniz mümkün.
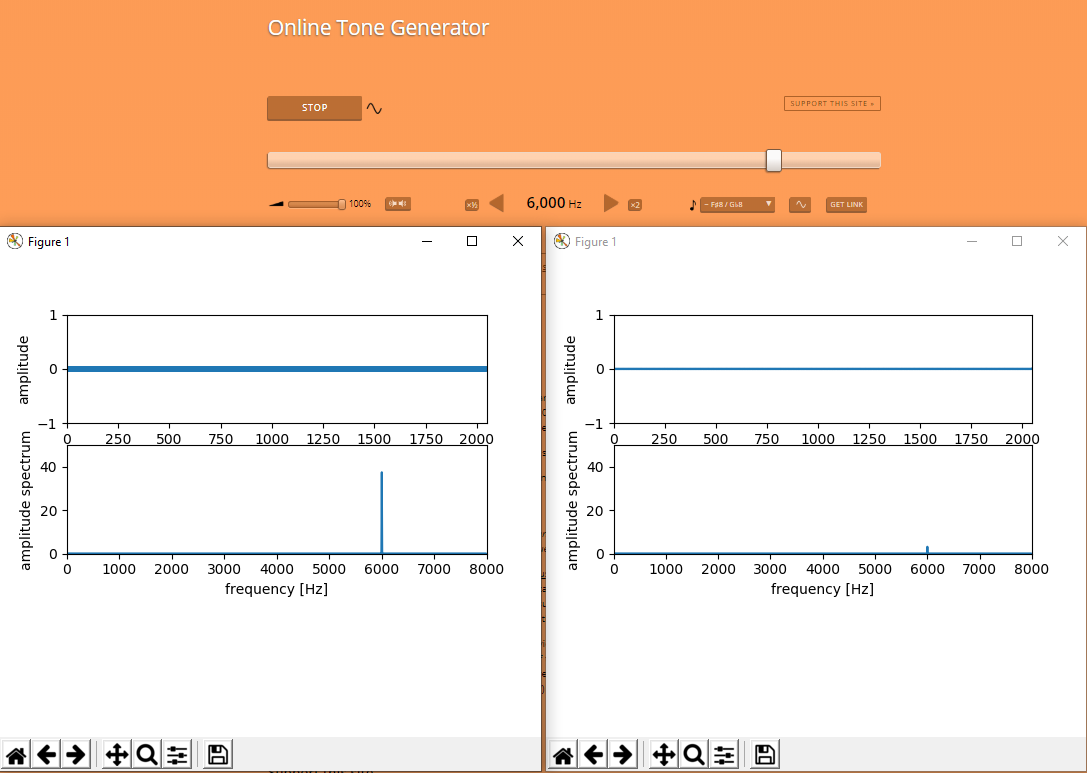
Tabi böyle kuru kuru olmaz dimi ? O halde kendi bestem olan parçalarla sizleri baş başa bırakıyorum. Keyifli seyirler.
Projeye Github hesabım üzerinden ulaşabilirsiniz.
Esen Kalın.

Son yorumlar